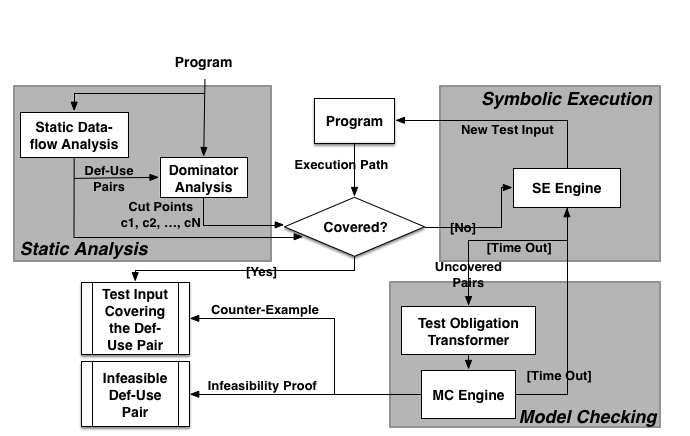
Data-flow testing (DFT) aims to detect potential data interaction anomalies by focusing on the points at which variables receive values and the points at which these values are used. Such test objectives are referred as def-use pairs. However, the complexity of DFT still overwhelms the testers in practice. To tackle this problem, we introduce a hybrid testing framework for data-flow based test generation: (1) The core of our framework is symbolic execution (SE), enhanced by a novel guided path exploration strategy to improve testing performance; and (2) we systematically cast DFT as reachability checking in software model checking (SMC) to complement SE, yielding practical DFT that combines the two techniques’ strengths. We implemented our framework for C programs on top of the state-of-the-art symbolic execution engine KLEE and instantiated with three different software model checkers. Our evaluation on the 28,354 def-use pairs collected from 33 open-source and industrial program subjects shows (1) our SE-based approach can improve DFT performance by 15∼48% in terms of testing time, compared with state-of-the-art search strategies; and (2) our combined approach can further reduce testing time by 20.1∼93.6%, and improve data-flow coverage by 27.8∼45.2% by eliminating infeasible test objectives. Compared with the SMC-based approach alone, our combined approach can also reduce testing time by 19.9%∼23.8%, and improve data-flow coverage by 7∼10%. This combined approach also enables the cross-checking of each component for reliable and robust testing results. We have made our testing framework and benchmarks publicly available to facilitate future research.
Our approach was built on four different tools, which are summarized as follows.
Our version of KLEE can be downloaded, which is adapted for data-flow testing.
| Name | Approach | Technique | Version |
|---|---|---|---|
| KLEE | Symbolic Execution | SE | v1.1.0 |
| BLAST | Model Checking | CEGAR | v2.7.3 |
| CPAchecker | Model Checking | CEGAR | v1.7 |
| CBMC | Model Checking | BMC | v5.7 |
We carefully constructed a repository of benchmark subjects for evaluating data-flow testing techniques. It includes subjects from four sources:
CBMC uses --unwind and --depth, respectively, to limit the number of times loops to be unwound and the number of program steps to be processed. The parameters used in our evaluation are listed below.
| Name | CBMC's --unwind | CBMC's --depth |
|---|---|---|
| factorization | 4 | 90 |
| power | 2 | 40 |
| find | 4 | 90 |
| triangle | 2 | 40 |
| strmat | 3 | 60 |
| strmat2 | 3 | 70 |
| textfmt | 25 | 700 |
| tcas | 2 | 200 |
| replace | 6 | 350 |
| totinfo | 15 | 250 |
| printtokens | 30 | 300 |
| printtokens2 | 12 | 450 |
| schedule | 5 | 350 |
| schedule2 | 5 | 250 |
| kbfiltr | 2 | 250 |
| kbfiltr2 | 2 | 300 |
| diskperf | 2 | 650 |
| floppy | 2 | 500 |
| floppy2 | 2 | 500 |
| cdaudio | 2 | 500 |
| s3_clnt | 13 | 500 |
| s3_clnt_termination | 13 | 400 |
| s3_srvr_1a | 10 | 200 |
| s3_srvr_1b | 4 | 100 |
| s3_srvr_2 | 15 | 1450 |
| s3_srvr_7 | 15 | 1450 |
| s3_srvr_8 | 15 | 1450 |
| s3_srvr_10 | 15 | 600 |
| s3_srvr_12 | 15 | 1500 |
| s3_srvr_13 | 15 | 1500 |
| osek_control | 15 | 1500 |
| space_control | 15 | 1500 |
| subway_control | 15 | 1500 |
In summary, our cut-point guided search (CPGS) strategy performs the best for data-flow testing. It improves 12∼40% data-flow coverage, and at the same time reduces the total testing time by 15∼48% and the number of explored paths by 28∼74%. Therefore, the SE-based approach, enhanced with the cut point guided search strategy, is effective for data-flow testing.
In summary, the SMC-based reduction approach is practical for data-flow testing. Both the CEGAR-based and BMC-based approaches can give consistent conclusions on the majority of def-use pairs. Specifically, the CEGAR-based approach can give answers for feasibility as certain, while the BMC-based approach can serve as a heuristic-criterion to identify hard-to-cover (probably infeasible) pairs when given appropriate checking bounds. In general, for data-flow testing, the CEGAR-based approach is more efficient on large and complicated programs, while the BMC-based approach is better for small/medium-sized programs.
In summary, the combined approach, which combines symbolic execution and software model checking, achieves more efficient data-flow testing. The model checking approach can weed out infeasible pairs that the symbolic execution approach cannot infer by 71.9%∼97.2%. Compared with the SE-based approach alone, the combined approach can improve data-flow coverage by 27.8∼45.2%. In particular, the instance KLEE+CPAchecker performs best, which reduces total testing time by 93.6% for all 33 subjects, and at the same time improves data-flow coverage by 36.5%. Compared with the CEGAR-based or BMC-based approach alone, the combined approach can also reduce testing time by 19.9∼23.8%, and improve data-flow coverage by 7∼10%.
For more information, please feel free to contact us: Ting Su, Chengyu Zhang, Yichen Yan.
Last modified: 2019.3